Dans ce cours on va étudier un bloc Article qui affiche le résumé d’une publication, avec l’image, l’auteur et la catégorie. On verra également comment créer un composant de recherche d’article, ce qui nous permettra d’aborder les hooks React, essentiels lorsqu’on fait des requêtes Ajax asynchrones.
Sommaire du cours
- Présentation du bloc
- Le moteur de recherche : un composant React
- La librairie Throttle-Debounce
- Chercher un article via l’API Rest de WordPress
- Le hook React useState
- Renvoyer les données du composant au bloc
- Affichage de l’article dans le bloc
- Le hook React useEffect
- Le rendu en front, en PHP
- Mise en pratique : le bloc et le bouton produit
Présentation du bloc
Dans ce cours plutôt conséquent, on va faire un bloc capable d’aller chercher un résumé d’article, ce qui nous permettra d’aborder plusieurs sujets très intéressants.
Vous retrouverez le code de ce bloc dans le dossier src/19-post du plugin qui accompagne cette formation, disponible sur Github.
Et contrairement au cours sur le bloc dynamique, on va pouvoir cette fois choisir l’article à afficher. Pour cela, on va créer un composant de recherche que l’on mettra dans l’inspecteur.
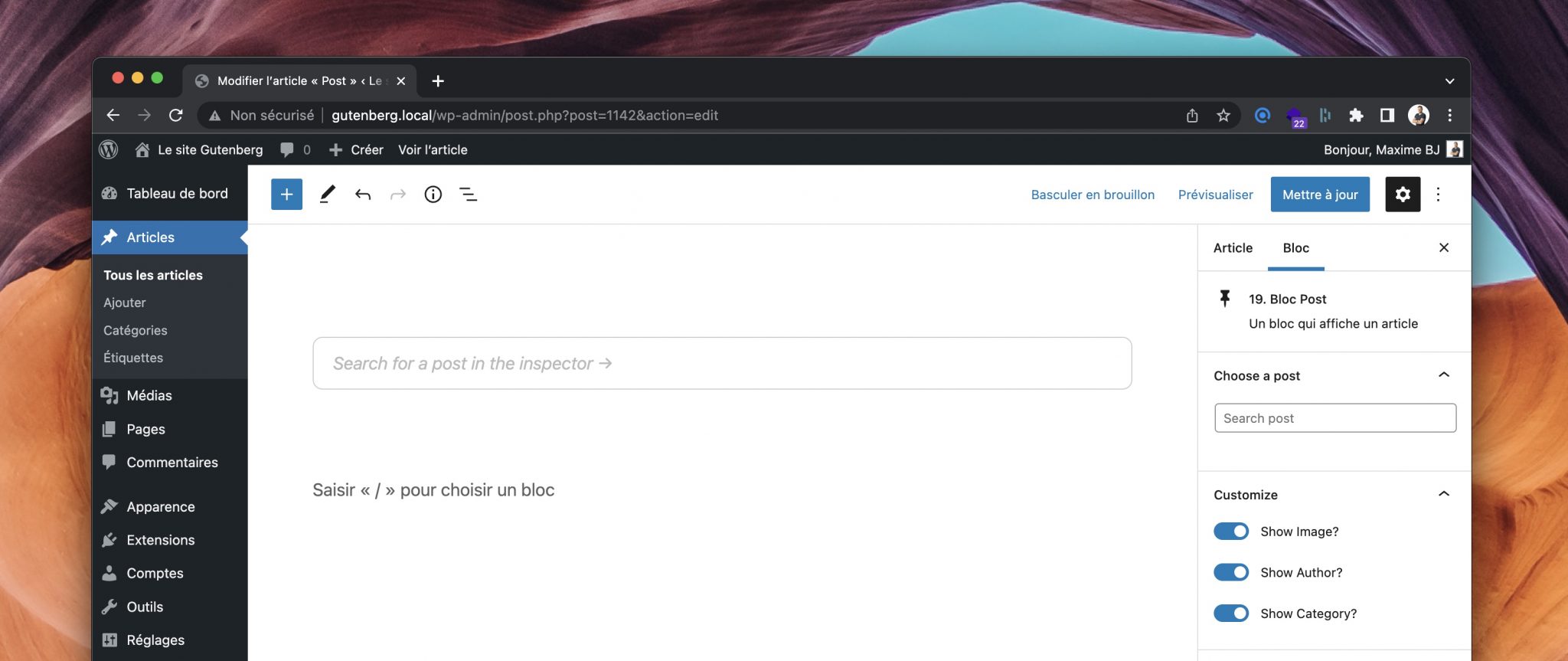
Voici à quoi devrait ressembler notre bloc :

On peut voir le composant de recherche à droite qui nous permet de sélectionner un article de notre blog. Il y a également quelques options pour afficher ou non l’image mise en avant, l’auteur et la catégorie.
Au niveau des attributs, on n’aura pas grand chose. Le plus important est de stocker l’identifiant de l’article qu’on aura sélectionné, ainsi que les valeurs booléennes pour afficher ou non les différents éléments :
Ce bloc nous permettra d’aborder plusieurs concepts importants, et intéressants :
- L’utilisation de l’API Rest de WordPress tout d’abord, pour aller chercher un article ;
- Le fonctionnement asynchrone et les Hooks React ;
- La création d’un composant réutilisable : le moteur de recherche ;
- Et enfin la récupération des attributs pour l’affichage du bloc dynamique en PHP.
Et on va commencer directement par notre composant de recherche, qui se trouve dans l’inspecteur.
Le moteur de recherche : un composant React
Dans l’approche React, tout est un composant. Et par définition, un composant est facile à transférer dans un autre projet, car réutilisable.
Du coup, un composant embarque toute la logique dont il a besoin : le HTML, le CSS et bien évidemment le JS. Il doit pouvoir fonctionner indépendamment du reste du code.
Chaque bloc de Gutenberg est d’ailleurs un composant : il peut fonctionner dans n’importe quel projet. Ce sera la même chose pour ce champ de recherche : c’est un composant d’interface qu’on pourrait réutiliser entre les blocs ou les projets.
C’est pour cette raison qu’on ne va pas placer le code de ce composant dans notre bloc, mais à l’extérieur de celui-ci afin qu’il soit complètement indépendant.
Pour rappel en React, un composant s’appelle comme une balise HTML. Ici, notre composant de recherche s’appelle <SearchPost>.
On peut bien entendu lui passer des paramètres (comme pour une fonction), que l’on appelle également des attributs, ou encore des props.
Dans mon exemple j’en ai 3 :
- L’attribut
onChangepermet de récupérer l’identifiant de l’article que l’on aura sélectionné ; - Le
postTypepermet de définir le type de publication dans lequel on veut faire une recherche d’article ; - Et enfin le
placeholderpermet de définir l’intitulé du champ de recherche.
Et comme vous pouvez le constater, j’ai bien rangé ce composant à l’extérieur du bloc : l’import en début de fichier retourne dans un dossier parent via ../components.
Il n’y a pas de règle absolue pour l’organisation de vos dossiers, mais vous pourriez très bien créer :
- Un dossier
/components/pour vos composants réutilisables ; - Un dossier
/blocks/pour vos blocs ; - Et un dossier
/styles/pour vos variables CSS et styles communs.

Si vous procédez ainsi, n’oubliez pas de changer les chemins dans index.js : il faudra ajouter /blocks/ à chaque ligne.
Dans notre cas, j’ai laissé les blocs à la racine par mesure de simplicité. Mais lorsque votre projet deviendra plus conséquent, il faudra bien réfléchir à l’architecture des fichiers de votre plugin.
Il suffit de regarder le Git du projet Gutenberg pour voir à quel point le rangement est important pour s’y retrouver parmi les milliers de dossiers !
Lorsque vous ajoutez le bloc 19 à un article, celui-ci va vous inviter à effectuer une recherche depuis l’inspecteur. Une fois votre saisie terminée, la recherche se lance automatiquement et les résultats s’affichent en dessous :

Bien entendu, pour que ça fonctionne correction, pensez bien à publier quelques articles en amont.
La librairie Throttle-Debounce
Comme vous avez pu le voir, je n’ai pas mis de bouton Rechercher à la suite du champ de recherche : je souhaite que la recherche se lance au fur et à mesure de la saisie.
Mais on va faire face à un souci de performance car dans cette configuration, une recherche sera lancée en Ajax à chaque caractère tapé au clavier par l’utilisateur.
Alors pour éviter cela on va utiliser un package npm qui s’appelle throttle/debounce et qui s’installe en ligne de commande via :
La fonction Throttle s’exécute avec un intervalle régulier, afin par exemple de limiter les lancements d’événements lors d’un scroll.
Mais c’est la fonction Debounce qui va nous intéresser ici. Elle permet de retarder le lancement d’une fonction. Lors de la saisie au clavier, cela permet d’attendre un peu, pour voir si l’utilisateur a encore quelque chose à taper, avant de lancer la recherche.
J’ai fixé ce temps à 300ms : si l’utilisateur ne tape pas un nouveau caractère à l’issue de ce délai, alors la recherche va se lancer.
À l’utilisation c’est plutôt simple, il suffit d’appeler Debounce en amont de votre fonction :
Lorsqu’on fera une saisie dans le champ TextControl, il lancera notre fonction search depuis l’évènement onChange.
Ensuite, Debounce marquera un temps de pause de 300ms pour vérifier si la saisie est bien terminée, et lancera enfin la fonction.
Pour l’instant, à l’intérieur, je n’ai qu’un console.log() pour vérifier que je récupère bien la valeur saisie par l’utilisateur.
Je vais également contrôler que la saisie comporte bien au moins 3 caractères : en dessous, je juge qu’il n’est pas intéressant de lancer une recherche.
Chercher un article via l’API Rest de WordPress
Maintenant, on va voir comment lancer une recherche en Ajax via l’API Rest. Et en fait, c’est très simple car WordPress nous fournit tout le nécessaire !
On va utiliser la méthode apiFetch à laquelle on va fournir l’URL que l’on veut requêter, puis récupérer le résultat dans then.
Gardez bien à l’esprit que ce code est asynchrone : ce qu’il se passera dans le then se déroulera quelques millisecondes après avoir lancé la requête, et non pas instantanément après.
Si vous avez besoin de savoir comment fonctionne l’API Rest de WordPress, j’ai écrit un cours complet à ce sujet dans la formation développeur de thèmes :
Pour la suite, on va aborder un nouveau concept qui va nous aider lorsqu’on fait de l’asynchrone : les Hooks React !
Le saviez-vous ?
Dans le cours sur le bloc Dynamique (bloc 15), on avait utilisé getEntityRecords, qui fait office de WP Query pour JS. Ici, j’ai préféré vous montrer l’utilisation de l’API REST. Mais ça aurait tout aussi bien fonctionné avec l’autre méthode !
Le hook React useState
Là où le JavaScript peut causer des noeuds au cerveau, c’est par son fonctionnement asynchrone : tout le code ne s’exécute pas de haut en bas, dans l’ordre dans lequel il est écrit.
C’est parce que JS est avant tout un langage par événements : des fonctions se lancent lorsque l’utilisateur rempli un champ, clique quelque part, survole une zone… C’est ce qui distingue JS d’autres langages comme PHP.
On peut le constater avec notre champ de recherche : la fonction de recherche se lance 300ms après la dernière saisie clavier de l’utilisateur, et les résultats n’arriveront que plus tard, lorsque le serveur aura répondu.
React est conçu pour gérer tout cela facilement : lorsque les résultats de recherche tomberont, l’affichage du composant devra être mis à jour. Et pour cela, on va simplement indiquer quelle variable surveiller grâce à useState().
Analysons maintenant ce code :
Tout d’abord on charge la librairie useState de React, qui nous permet de surveiller certaines données dans notre composant.
Ensuite, on déclare une variable results qui contiendra nos résultats de recherche, et une fonction setResults() qui nous permettra d’assigner ces résultats à la variable. On ne l’assignera donc pas via l’utilisation d’un égal (=) classique.
Le false dans useState indique qu’on ne veut pas attribuer de valeur par défaut à notre résultat : il est vide tant qu’on n’a pas fait de recherche.
Dans notre fonction de recherche, on commence par assigner une chaine “Chargement” à nos résultats via la fonction setResults(). Cela indique à notre composant que la valeur a changé, et qu’il doit mettre à jour l’affichage du composant.
On retrouve également setResults lorsque la requête API est terminée :
- Soit il n’y a aucun résultat, et on change la valeur de
resultspar « Aucun Résultat » ; - Soit il y a des résultats, et alors on stocke les articles dans
resultsqui devient alors un tableau contenant des articles.
On regarde ensuite dans le return :
Si results est une chaine de texte (chargement ou aucun résultat), alors on l’affiche dans un paragraphe. Essayez sur votre bloc : vous devriez voir apparaitre “Chargement” brièvement pendant que la recherche est en cours.
Lorsque la recherche est terminée et que des résultats ont été retournés, alors result est un tableau : on itère dessus pour afficher le titre de chacune des publications trouvées.
D’ailleurs on aurait très bien pu gérer ça avec 2 variables différentes : une pour l’état (chargement, aucun résultat) et une dédiée exclusivement aux résultats. Mais c’était plus malin de tout faire en une seule !
Le saviez-vous ?
En général avec React, lorsqu’une fonction commence avec use, c’est que c’est un hook.
Je résume :
Lorsqu’on veut que le composant rafraichisse son affichage lorsqu’une donnée est modifiée, on utilise le hook React useState.
Pour cela on déclare une variable qui va stocker cette valeur : result par exemple, ainsi qu’une fonction pour mettre à jour cette valeur : setResult.
C’est React derrière qui va gérer cette fonction. Ici, on ne déclare que le nom qu’on veut qu’elle ait.
Désormais, dès qu’on met à jour une valeur via setResult, le composant sait qu’il soit mettre à jour l’affichage à l’écran. Malin non ?
De cette manière, le composant n’a pas besoin de se redessiner au moindre changement d’état, et on conserve ainsi d’excellentes performances.
On réutilisera cette logique de hooks dans le bloc, pour aller chercher d’autres informations de l’article.
Renvoyer les données du composant au bloc
Bon, on a un composant autonome capable de faire une recherche dans les articles grâce à des requêtes Ajax via l’API de WP, qui se rafraichit grâce à un hook React. On peut donc continuer.
La nouvelle problématique qui se pose à nous c’est de faire remonter notre sélection au bloc parent.
Dans le composant de recherche, on affiche les résultats sous forme de tableau :
Chaque ligne est un <li> qui affiche le titre de l’article, et possède un évènement onClick, qui renvoie l’identifiant de l’article en amont :
Mais c’est où en amont ? Il sort d’où ce onChange ? Pour cela il faut remonter sur notre bloc Post et plus précisément dans l’inspecteur, là où on avait appelé notre composant <SearchPost> :
C’est ici en fait qu’on avait déclaré le onChange ! Voici donc ce qu’il se passe :
- Dans le composant, lorsqu’on clique sur un résultat, on appelle la fonction
onChangeet on lui passe l’identifiant de l’article. - Dans l’inspecteur, on récupère cet identifiant et on l’assigne à l’attribut
postID.
Du coup là, il y a un concept très important : le composant est seulement conçu pour renvoyer un identifiant d’article. C’est tout.
C’est le bloc qui ensuite va assigner cette valeur à un attribut. De cette manière, le composant reste complètement indépendant, et pourra être réutilisé ailleurs, là où d’autre blocs auront d’autres attributs.
D’ailleurs le choix du nom onChange est totalement arbitraire : j’aurais pu l’appeler autrement. Mais ça permet d’être cohérent avec les autres champs comme le <TextControl> par exemple.
Si vous passez en mode code, vous verrez que le HTML généré par votre bloc est tout simple :
Il y a seulement un commentaire, qui contient l’identifiant de l’article à afficher, et qui vient de nous être transmis par le composant de recherche.
Aparté: Pourquoi on stocke uniquement l’identifiant de l’article ?
Le fait de stocker uniquement l’identifiant de l’article nous obligera à faire une nouvelle requête pour récupérer ses contenus. Mais on n’a pas le choix : si on venait à stocker toutes les données de l’article dans le bloc, alors celui-ci afficherait des informations potentiellement obsolètes lorsqu’un auteur changerait son contenu.
En stockant uniquement l’identifiant de l’article, on s’oblige à aller cherche à chaque fois les informations les plus à jour, et on évite de stocker en double des données, ce qui est une très mauvaise pratique en programmation.
En front, ça fera une requête de plus bien entendu, mais avec un système de cache, il n’y aura pas de soucis de performances.
Affichage de l’article dans le bloc
Retour à notre bloc Post maintenant. On va regarder du côté de edit.js dans un premier temps :
On observe 2 cas de figures ici :
- Soit on a déjà sélectionné un article, et auquel cas on souhaite l’afficher ;
- Soit on n’en a pas encore choisi, et on va à la place afficher un message invitant à faire une recherche dans l’inspecteur.
Pour ce second cas, j’ai crée un composant <Message> qui permet d’afficher une information à la place du bloc.
Donc tant qu’on n’aura pas sélectionné un article via notre composant <SearchPost>, ce message apparaitra.
Mais dès que ce sera fait, c’est là que ça devient intéressant : on va aller chercher toutes les informations de notre article, et afficher l’aperçu du bloc.
Allons maintenant faire un tour du côté de block.js, car c’est ici que l’on retrouvera la plus grosse partie du code.
Dans ce bloc, on va récupérer les données de l’article grâce à l’identifiant fourni par <SearchPost> et enregistré dans l’attribut postID du bloc. Celui-ci est transmis au composant via les props.
De là, on va pouvoir faire une requête API pour récupérer les données de l’article. Mais le souci, c’est qu’elles seront incomplètes !
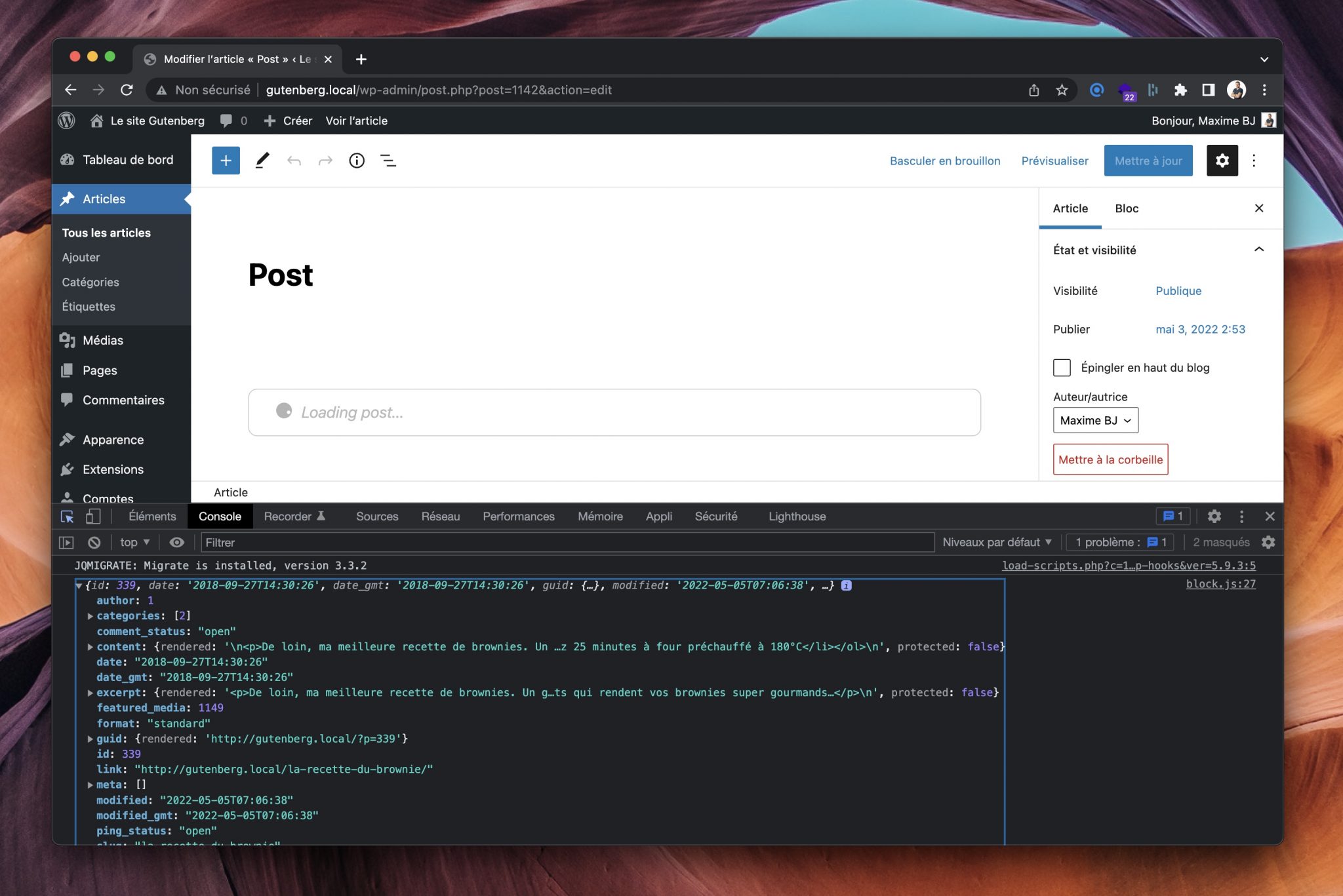
On observe notamment que pour l’auteur, seul son ID nous a été fourni. C’est la même chose pour l’image mise en avant, ainsi que pour les catégories.
Il nous faudra donc faire d’autres requêtes API à partir de ces ID pour récupérer toutes les informations. Dans l’ordre, ça se passera comme ça :
- Lorsque le bloc reçoit un nouveau
postID, il lance une requête API pour récupérer les données de l’article. - Une fois les données de l’article reçues, 3 nouvelles requêtes vont être lancées pour récupérer l’auteur, la catégorie et l’image mise en avant.
Et le bloc se mettra à jour à chaque fois qu’une requête sera terminée.
Le saviez-vous ?
Des technologies comme GraphQL permettraient d’éviter d’avoir à faire plusieurs requêtes API comme on le fait. Mais on n’a pas besoin de sortir l’artillerie lourde pour notre exemple.
Le hook React useEffect
Dans notre bloc, on va réutiliser les hooks React avec la fonction useState() et on va en profiter pour en aborder un nouveau : useEffect().
Comme on l’a vu, le changement de données ne va pas être dû à une action directe de l’utilisateur sur ce composant, contrairement au composant recherche. Mais son état va cependant changer lorsqu’il recevra un PostID.
Dans ce cas, l’affichage du composant devra être mis à jour : il aura besoin pour cela de lancer une requête API pour récupérer les informations de l’article (pour rappel, on n’a transmis que l’ID de l’article, il faut donc faire une requête pour récupérer l’article).
Le hook useEffect va nous permettre de justement lancer une fonction lorsqu’une donnée change. Par exemple :
Pour la première ligne, si le postID est modifié, alors on lance la fonction getPost() afin de récupérer l’article correspondant. Pour la seconde, c’est seulement lorsque l’objet post aura changé que sera lancée la fonction getAuthor().
Et ça correspond bien à ce que l’on a besoin de faire : dans un premier temps, récupérer les données de l’article. Et ensuite, dans un second temps, récupérer l’image mise en avant, l’auteur et la catégorie, comme ces informations ne sont pas fournies en totalité avec la première requête (juste les ID).
On peut d’ailleurs observer les différentes routes API utilisées pour l’occasion dans les différentes fonctions asynchrones :
Comme on n’obtiendra pas toutes ces informations instantanément, on peut prévoir là aussi afficher un <Message> pour indiquer que l’article est en cours de chargement.
Le second attribut withSpinner me permet d’ajouter une animation de chargement (un cercle qui tourne) grâce au composant <Spinner> fourni par WordPress.
Et du coup notre fonctionnement asynchrone est opérationnel !
Je résume là encore :
Lorsque postID change (via les props dans notre cas), je lance getPost(), ce qui modifiera l’objet post, ce qui lancera ensuite getAuthor().
Dans getPost() et getAuthor(), je mets à jour l’état via setPost() et setAuthor(), ce qui aura pour effet de rafraichir le rendu du composant dans le navigateur.
Le rendu en front, en PHP
Tout comme pour notre bloc dynamique vu précédemment, on va avoir besoin de générer le rendu en PHP au dernier moment, afin d’avoir les dernières informations à jour de l’article que l’on souhaite afficher.
Et on va maintenant étudier la fonction correspondante, qui est plutôt conséquente, et qui reprend une partie de la logique déjà écrite en JS (mais on n’a pas le choix) :
La première chose à faire, c’est de récupérer l’identifiant de l’article via les attributs, passés en paramètre de la fonction par WordPress.
On va ensuite lancer une WP Query classique, comme on a pu le voir sur le cours dédié à la WP Query dans la formation développeur de thèmes.
On récupère ensuite l’image à la une au format moyen, l’auteur et la catégorie s’ils existent et si on a décidé de les afficher dans le bloc. Pour cela on vérifie les valeurs booléennes fournies par les attributs. Par exemple showAuthor.
Vient ensuite le moment de générer le template. Et pour cela on va utiliser l’object cache de PHP via les fonction ob_start(), ob_get_contents() et ob_end_clean(). On utilise ces fonctions lorsqu’on a besoin de retourner une variable PHP (notre HTML) mais qu’on veut inclure un template.
Par défaut le template est affiché à l’écran comme un echo. Mais là on ne veut rien afficher pour le moment, car on veut renvoyer son HTML à WordPress (qui l’affichera en temps voulu). Sinon, il aurait fallu faire quelque chose comme ça, avec de la concaténation :
Autant c’est jouable avec peu de HTML, mais là on a quand même pas mal de markup à générer. Il suffit de voir le contenu de template/post.php.
Dans le template, on retrouve les fonctions classiques de la boucle WordPress comme the_title et the_permalink(), à savoir les templates tags.
Si je résume : tout le HTML généré et affiché est récupéré par les fonctions ob_, et stocké dans une variable au lieu d’être affichées à l’écran, qui sera ensuite renvoyée à WordPress.
Essayez d’afficher votre article sur votre site en front : si tout s’est bien passé, il devrait apparaitre ! Tentez de modifier l’article original et retournez voir votre bloc : son contenu sera bien à jour.
Mise en pratique : le bloc et le bouton produit
Sauriez-vous utiliser le même principe pour créer 2 nouveaux blocs ? Voici ce que vous pourriez faire en utilisant la même logique :
- Un bloc bouton permettant d’afficher le titre d’un produit, ainsi que son prix ;
- Un bloc produit qui va afficher un produit WooCommerce, accompagné d’un bouton d’ajout au panier.

Vous allez pouvoir réutiliser le composant <SearchPost> et le contraindre cette fois au type de publication Produit.
C’est là où vous pourrez vous rendre réellement compte de l’avantage de l’approche composant : on ne passe plus son temps à réinventer la roue, mais on réutilise intelligemment l’existant !
Pour le reste, c’est en général la même logique !
Voilà un cours bien conséquent ! Vous savez désormais créer des composants réutilisables, utiliser les Hooks React, requêter l’API REST de WP et gérer des flux de données asynchrones.
On a même pu intégrer facilement la librairie Debounce/Trottle qui améliore l’ergonomie de notre moteur de recherche.
Dans le cours suivant on va voir le bloc Plugin qui va piocher cette fois sur une API Rest distante. On verra qu’en général le principe reste le même.
0
Questions, réponses et commentaires